I am a senior machine learning engineer, specialising in deep learning, with roots in software development. As I started in development, I have a solid foundation of programming best practices and my machine learning knowledge is built on top of this, rather than the other way around.
I have worked in an entirely remote environment across many time zones for several years and have worked in companies ranging from 2 to ~20,000 employees. This has given me the experience of working with both technical and non-technical team members and I've learned to communicate effectively across this boundary.
Whilst working towards my PhD in object-tracking and time series analytics, I co-founded two startups, where I learned to take on a highly varied number of roles and responsibilities. My current work involves a lot of data pipelines, ML & NLP, web scraping and custom language models.
Though I have extensive experience in Computer Vision, Time Series Analysis, and Natural Language Processing, my interests also lie in DevOps/MLOps, and privacy-preserving AI.
Feel free to send opportunities via email or Twitter DMs
As one of the first hires, I lead the design, development and deployment of the core data collection pipeline. This was achieved through a combination of web scraping, machine learning and natural language processing (NLP) models, many of which were custom-built.
The models that were built primarily consisted of named entity recognition, sentiment analysis, and text classification on both large and small bodies of text. Additionally, I also trained a language model from our large selection of domain-related documents using unsupervised learning. This model was used in place of generalised large language models (such as GPT3) that lack specific domain-level nuances. These models were then made production-ready, turned into APIs and deployed to Kubernetes as real-time endpoints with high scalability.
Alongside my technical role, I also contributed to the high-level planning and direction of the company, produced data and talking points for investor updates, and regularly coordinated projects with other teams within the company. I was also responsible for managing a team of contractors that were assisting in our data collection capabilities.
I worked on the development of a method for cancer detection using deep learning that requires only a smartphone. We localised the blood cells in an image, segmented and classified the different types of blood cells, and then determine if there were signs of cancer.
At Fair Custodian, along with my responsibilities as Co-Founder, I lead the research and implementation of our intellectual property. As part of this, I developed a highly-scalable pipeline to extract the key information from customer's emails using machine learning and NLP so that it could be presented to them in a concise format.
Research Analytics, an AI consultancy, was my first startup. My responsibilities ranged from business management to training and deploying models. One project was to design and implement a camera-based crowd analytics system that could track factors such as gender and age on the edge device, whilst maintaining people’s privacy.
Here I worked in a large-scale partnership that spanned many universities and businesses all over Europe. My project focussed specifically on the early detection of health and welfare problems in pigs. I worked with the research associates to develop a means for video collection, storage, and analysis in a remote location with minimal power and networking infrastructure.
I worked as a C# developer on an internal project designed to maximise productivity and make the lives of staff as easy as possible. My primary responsibilities were implementing an effective git workflow, liaising with the team to plan new features, and ticket resolution.
At CERN I was a developer on the Invenio project; an open-source digital library framework, written in Python using the Flask framework. This software is used internally at CERN and at other institutes such as CalTech and Berkley Law. We worked in a typical agile workflow with weekly meetings with the full development team to review each other's progress, otherwise the development team was left to work on their individual tasks. I came to enjoy this working style as it gave me the freedom to explore innovative solutions to the challenges we had, which drastically improved my skills as a developer.
My research focussed on how the latest research in deep learning architectures could be applied directly to the farming industry. For the first half of my research, I developed a novel approach to multi-sensor anomaly detection using a Recurrent (GRU) Autoencoder that fused data from multiple environmental sensors. This fused data was used to determine when there were likely to be outbreaks of disease. Following on from the promising results achieved by this approach, I repeated this experiment using a CNN-based autoencoder and multivariate transformer.
The second half of my research focussed on using inexpensive cameras to track individual pigs as they move around a pen without requiring any special hardware. Previous approaches typically tracked the pigs as a group as it is very difficult to tell pigs apart simply by their appearance. However, this made it very challenging to provide healthcare tailored to the individual pig. The method presented in my thesis shows that Deep Learning methods are very capable of tracking individual pigs over time. Three Deep Learning models were trained using custom datasets to assist with: detecting the pigs in an image, tracking them as they move around, and recovering identities if they are temporarily lost.
Both of these core components of my thesis resulted in open access publications.
Artificial Intelligence pathway
Notable projects include:
Allows users to plan an upcoming trip where all place names in the plan are automatically detected, added to a map and place details are loaded. Users can also generate itineraries using a query such as "Give me a 3 day plan for a couple in New York".

This implementation made use of Faster R-CNN to localise the pigs within an image. Each pig is then assigned an identity, which is tracked over time using a combination it's current trajectory and it's visual appearance using CNNs.
This work was then extended to use CNN-based re-identification methods that allowed the tracker to recover from long-term occlusions. The success of this implementation would theoretically allow the method to work across multiple cameras, however I did not have enough multi-camera data to accurately test this, which is why I focussed specifically on "tracklet stitching" (concatenating two tracked objects if they are the same identity).
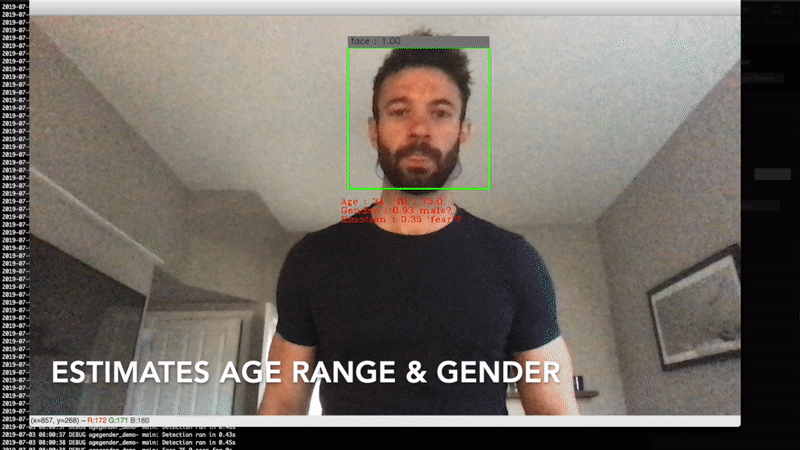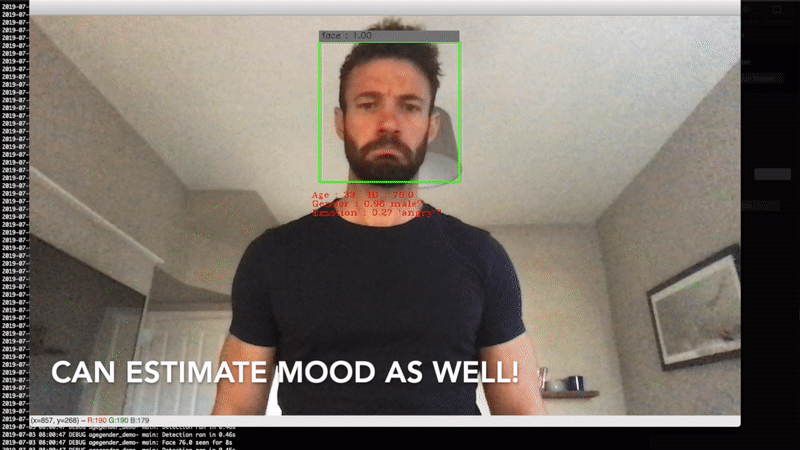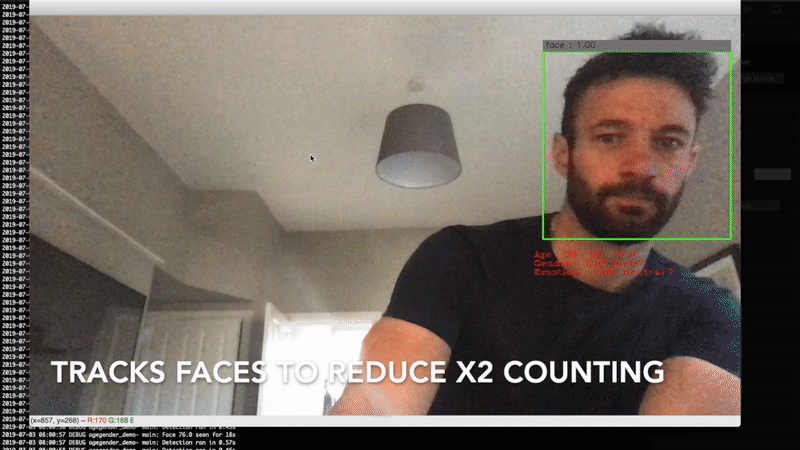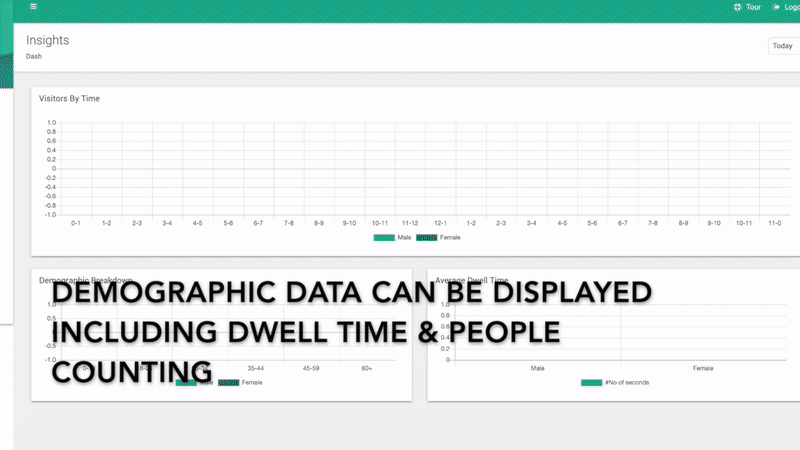
I worked with a client to develop a privacy-focused crowd analytics device that estimated the age and gender of people in the vicinity of one of their advertising screens. This information was then fed back to the advertisers so they better understood the demographics of who was seeing their advertisements.
As we wanted to be as privacy conscious as possible, all of the data processing was done on the edge device (a Raspberry Pi with a camera module), meaning that we only stored the images for a fraction of a second as we processed them, and only aggregate statistics were sent to the cloud.
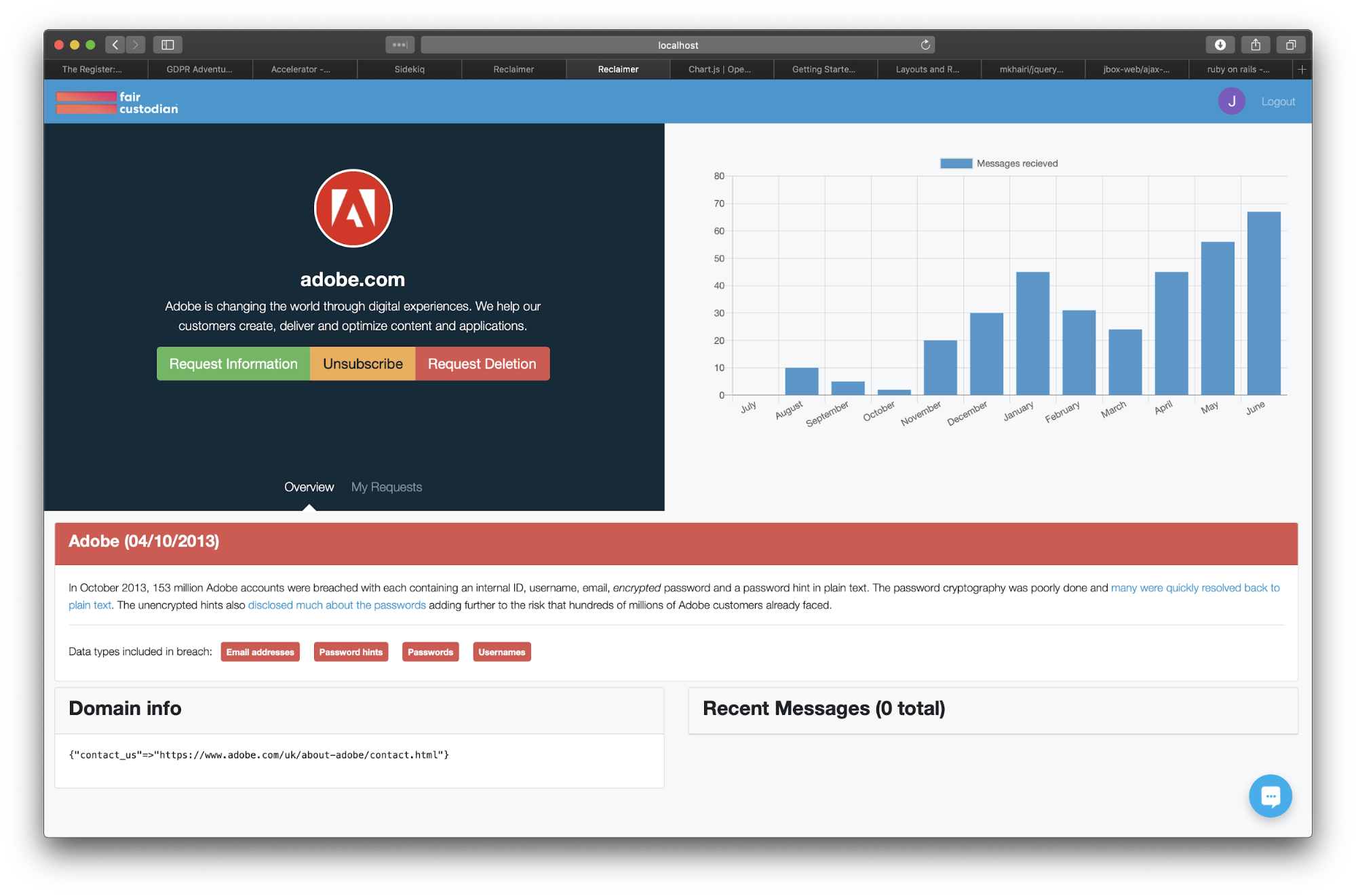
Reclaimer allowed users to find all the places they have accounts online and either unsubscribe from each place's marketing material, request a copy of their data or request all their data be deleted all with a single click.
Nope allowed users to generate email addresses for every site they sign up to in order to improve their privacy when signing up to new services.